Most yes/no questions in server administration have the wonderfully vague answer of “it depends”. This question, however, does not. Unequivocally: yes, server administrators should learn to code. If you got into this line of work because you enjoy computing but don’t want to program, take heart. You do not need to achieve anything like the proficiency of a full-time software developer. Also, “coding” might not mean what you expect.
[citationic]
Why Should Server Administrators Learn to Code?
Let’s immediately get the basic answer out of the way. Three core reasons make coding ability indispensable:
- You cannot avoid the command line or writing scripts and perform quality work
- You will use scripts prepared by others, and you need the ability to audit them, which means understanding them
- All your servers run software; understanding software construction helps you to locate problems quickly
More than a few administrators resist. They’ll need to accept that they have artificially limited themselves. Technology advances more quickly than anyone can develop a solid GUI. In my daily use, the Hyper-V virtual switch has existed for over a decade and the graphical tools have never caught up to its PowerShell interface. With “infrastructure as code” tools such as Ansible and Terraform, systems administrators deal with more code than ever. Perhaps you can run a small environment without learning code, but that should appeal mostly to small business owners trying to wear all the hats at once. Even in the simplest cases, complete ignorance of coding will hurt.
No one has summarized it better (if harshly) than Jeffrey Snover (father of PowerShell):

If you, as a server administrator, won’t learn to go beyond the graphical interface, then your job will only last until your employer realizes that you can’t do anything more than they could do without you. Sure, some admin jobs work with highly developed server software that relies on a graphical interface. What happens if that job goes away?
However, let’s not forget a point from the introductory paragraph: coding might not mean what you expect.
Coding? Programming? Scripting? What’s the Difference?
I do not remember a time before the argument over the distinction between “programming” and “scripting”. While not a new term, the use of “coding” has grown dramatically in recent years. The word that you choose mainly depends on your audience.
The easy one: if we accept that “programming” and “scripting” both involve writing code, then “coding” works in all situations. Not everything that counts as “programming” involves written code, though. Once upon a time, “programming” was punching holes in cards. But, the pattern of holes forms a code, so that still counts as coding. But, as we’ll discuss, “coding” can extend beyond both programming and scripting.
We can’t easily distinguish programming from scripting. However, we don’t need to involve ourselves in the argument. Historically, I have mostly seen it used by people that consider themselves “real programmers” using “real programming languages” to mock and diminish others. The category of “real programming languages” has shifted dramatically over time. Assembly programmers held their status over C programmers who held their status over Java programmers who held their status over C# programmers who held their status over Visual Basic programmers. That doesn’t count hundreds of other languages that appear at some level of this arbitrary hierarchy. So, people that look down on “lesser” languages tend to show extra scorn for “scripting” and do not accept it as “programming”.
We’ll take a bit of time to examine some of the “differences” between programming and scripting, but if you just want to read about the subject in the article’s title, skip ahead of the next two subsections.
Examining the Arguments to Separate “Scripting” from “Programming”
I intend to use this sub-section to show that “scripting” and “programming” only have arbitrary differences. I want systems administrators to walk away from this without worrying about anyone granting or withholding a “real” label. If you really care about this topic, then you will find some nuance or nitpick. I cannot put the controversy to rest because too many people have too much emotional investment. What really matters: you have a job to do; use the tool that does the job most efficiently for you.
Some of the arguments:
- Scripting is for automation: Programming is also for automation. Every time we get a machine to do something, it counts as automation. Using a table saw to cut through a piece of wood automates the cutting process. Driving your car to work automates the travel process. Sometimes people argue over the degree of automation, but any Turing-complete language, whether “programming” or “scripting”, can automate as well as any other. If people can’t accept that, then every language used by programmers except raw binary (or hex) automates a compiler or interpreter. That means that “programming” means writing a script for the compiler or interpreter to follow. So, programming is scripting.
- Programming languages are faster than scripting languages: Simply answered: not really. A computer language has no inherent speed implications. All code, regardless of source, becomes machine code. How it gets there influences the speed, not the language that started the process. Technological advances have made this argument nearly moot. As a longtime administrator of virtualized server and desktop systems, I can tell you that your software doesn’t work that hard.
- Programming languages are compiled; scripting languages are interpreted: This is another form of the previous argument about speed. Pick a “scripting” language, and if someone hasn’t already made a native compiler for it, then someone could. The existence or lack of a compiler may influence your decision when trying to select a tool for the job at hand, but the language still matters more. I like C++, but I would use C# (partially compiled) or PHP (interpreted) for a website because of suitability.
- Very large programs don’t use scripting languages: This is historically true, but only because of the persistent “the way we do things” paradigm. PowerShell has the same features as languages used in large-scale projects. Also, what does one mean by “very large”? Very large PHP programs exist. Furthermore, most “very large” projects involve multiple languages, and scripting languages usually count among them.
- Scripting languages require some sort of pre-existing environment: This is another form of the “compiled vs. interpreted” argument. PHP programs require an interpreter. BASIC requires an interpreter. JavaScript requires an interpreter. However, Java requires a Java virtual machine and .Net languages require some flavor of .Net components, and consensus considers those “programming” languages. If you need more convincing, gather up all the assembly source code you can find. You’ll find that all of it falls into one of three categories: it bootstraps an operating system, it requires an operating system, or it requires another program to link it (which is very close to the “operating system” requirement in a less tightly scoped form). I do not know of any other language used to write bootstrap code. Even the Linux kernel, which uses C almost exclusively, has some assembly for bootstrapping. So, if not needing a pre-existing environment distinguishes a programming language, then only assembly counts.
- Programming languages are more complex: Compare C to any current “scripting” language. PowerShell, for example, dwarfs C in complexity. To be fair, I have seen some people say that they use C as their scripting language. But, they’re really making the same point as this section.
- No, we meant that programming languages are more complex to learn!: No, they’re not. You could spend just as much time mastering JavaScript or PowerShell as C. Scripting languages have different complexities and nuances, but there is more difference within the accepted categories of “programming” and “scripting” than between the categories. As an example, the complexity difference between C# and PowerShell is less than the complexity difference between C# and C++, and the difference between those two is greater than the distance between either of them and PowerShell.
If none of that works for you, then consider this:
- “Programming” (common definition) is using a human-readable method to script a compiler to create machine code.
- “Scripting” (common definition) is using a human-readable method to program an interpreter to create machine code.
We can take that to real-world scenarios: the current Exchange API is PowerShell-only. So, programmers use languages like C# to generate and run PowerShell. Under the traditional terminology, is that programming or scripting? Code generators use all sorts of “scripting” languages to create high level and machine code. Is that programming or scripting?
Scripting and programming are interchangeable terms. All that’s left is for people to accept it. Or not. It doesn’t really matter. It can be fun to argue, but “winning” has no practical value. I enjoy the thought experiments, but they have no influence on how I use the available tools.
How “Code” Goes Beyond Scripting and Programming
Because jumping into the programming vs. scripting argument wasn’t enough, I’m going to jump into another controversy. Descriptive languages do not count as scripting or programming, but they do count as coding. Examples of what I mean by descriptive languages:
- XML
- HTML
- YAML
- CSS
Some people argue that these aren’t languages at all. However, they have syntax and semantics, so they qualify as “language” as much as any other computer language. They lack anything recognizable as an actionable machine instruction or actionable composites of instructions, though, so they do not fit in either common definition of “scripting” or “programming”, nor do they fit into the conjoined definition that I argued for above. I suppose someone could convince me that languages like HTML and CSS share the definition of a declarative language like SQL in that they tell the computer what the author wants done and leave it up to a compiler or interpreter to figure out how to do it. I think that’s a stretch, though, primarily because of the words “do” and “done”. One way or another, SQL statements tell the computer to do something. HTML just marks off and designates item types that an HTML parser recognizes. CSS can define behavior, but I’m not sure that it instructs an action. But, if it really matters to you, then I would not put up much fight against classifying HTML and CSS writing as scripting or programming.
However you feel, I do not see any way to say that code doesn’t make up those languages, so writing them means “coding”.
Anyway, just like the previous section, arguing about this passes time but does not produce value. Let’s do something valuable.
Getting Started [Coding|Programming|Scripting] for Server Administrators
I do not care what you call this activity. If you talk about it to others and they understand what you mean, then you have unlocked The Great Naming Achievement.
I do care that you learn to code. Because this article explains “why”, I will minimize coding examples here. While I prepare some “how” articles, you have multiple ways to start on your own.
Comprehensive Administrators Have Met Assembly Language
If I had my way, every systems administrator would cut their teeth on assembly language. Assembly does not appear much even in the world of professional programming, so I have no expectation of a server admin memorizing it or gaining proficiency. Learning and writing some assembly helps you to understand how the machine does what it does. Knowing how the machine works gives you an enormous advantage when troubleshooting software. Other server administrators flail when presented with a problem where I do not. I can skip ahead because I first figure out what the software intends to do, then I think of ways that I would implement that in code. That informs me to troubleshoot with Wireshark or a disk scan or a network adapter diagnostic or whatever other tool applies most closely not to the symptom, but to the problem that causes the symptom.
The best resources that I have found for learning assembly language came from books, some no longer in print. One of my favorites was written by Randall Hyde, who also happens to have a recent book on my recommendations list. I have also found free resources online and will include them in the list.
- Randall Hyde’s Art of 64-Bit Assembly, Volume 1. As of this writing, volume 2 does not exist. I do not know if he has volume 2 planned or if he’s playing off of Michael Abrash’s Zen of Assembly Language which had a volume 1 but no volume 2. Since Hyde has other multi-volume works, I expect the former. However, volume 1 has more than you need for the purpose that I intend. This book uses Microsoft’s assembler, MASM (interestingly, the leading M stands for “Macro”, not “Microsoft”). You’ll need a Windows installation to get the most out of the book. It explains how to acquire and use MASM for free.
- NASM Assembly Language Tutorial: As a language tutorial, you can’t beat this, especially at its price point of 0. However, it dumps you right in and explains the concepts as you go. If you want something that gives more explanation with less code, look at my next suggestion. This tutorial uses the NASM assembler and depends on Linux system calls. Windows administrators can use the Windows Subsystem for Linux (WSL) to assemble and run the code and Visual Studio Code to write it from their desktop. To start quickly with these two tools, install both and set up a distribution in WSL (instructions are in the provided links). Start your distribution, which will place you in your user’s home directory. Type
code .(note the period). That will start up Visual Studio Code with a connection to the WSL instance in the directory where you started it (that’s what the period means). You can then use Visual Studio Code to create folders and files as necessary. It will also have a console opened directly into the instance, so you can assemble and run your programs in VSCode or in WSL. You’ll find assembly instructions in the tutorial. - Michael Schwartz’s Assembly “Tutorial”: I would not call this a tutorial. It has an excellent introduction to what assembly does, followed by good explanations of assembly’s components, and finishes up with a simple example.
I did not find any free text-based tutorials for assembly on Windows that I would recommend in this context. I found a few YouTube hits, but I did not vet them. However, I do not think that a systems administrator will find value trying to chase down a good tutorial for assembly on Windows. Someone who wants in-depth knowledge of assembly on Windows can justify paying for Hyde’s book or one of the other great works available. However, I did find a fantastic, free reference work that also involves C. I’ll talk about that near the end as it neatly folds in several other concepts that I want to show.
C Gives Server Administrators a Boost
If I had used C++ instead of C, that title would have made a great pun because there’s a library called Boost for C++. I basically made a dad joke for computers. Ha. However, I mean to talk about C, not C++. No matter what you might infer from the ubiquitous “C/C++”, C and C++ are distinct languages. I like C++, but it is not the best choice for occasional programmers. Its dependence on abstraction does not serve the purpose of this article as well as C.
C is little more than a veneer over assembly. It hands off tedious activities to the compiler but leaves most of the work to you. In the previous section, I mentioned the need for different material to learn assembly on Linux versus learning it on Windows. That’s because you need different codes to talk to the two different operating systems, even for simple things like ending the program. In C, you write the same code regardless of platform but use a platform-specific compiler to produce the final machine code (that’s why we say that C is “portable”).
I do not feel that learning C gives the same depth of understanding as learning to write assembly. However, unless you make a real effort to learn assembly, you quickly hit a point where you just type what the tutorial says without really following the concepts anymore. I don’t ask that from server admins. C stays close to the hardware without forcing you to spend so much time on implementation details that you forget what you wanted to do. Unfortunately, it also obscures almost all the machine code, so, alone, it quickly loses its value as a guide to learning about the system. Luckily for us, mainstream compilers can give us the best of both.
For my demonstration, I will use Visual Studio, which you can get for free in the Community Edition. I have a reason for this vs. a smaller open source package. The steps:
- When you install, pick the “Desktop development with C++” workload.
- Once installed, start Visual Studio. On the initial screen, click Create a new project.
- On the new project window, find the Console App entry that uses C++ as its language. You can use the filter drop-downs at the top to reduce the number of choices. Once you have selected the correct project type, click Next.
- Give the project any name and location that you like. I called mine “CDemo”, but it doesn’t matter. Click Create when ready.
- Visual Studio will open up a new project with a full “Hello World” application and a lot of comments. As it suggests, you can press F5 or Ctrl+F5 to instruct Visual Studio to compile and run the program. It makes no difference to these steps if you want to do that to see it in action. Just remember to close the window that shows the output when you’ve seen enough or you’ll have trouble later (because VS will want to make a new .exe in the same place as an already-running .exe).
- Find the Solution Explorer pane. It defaults to the right side of Visual Studio for C++ programs. In it, you will see your solution (the thing that I called “CDemo”). Right-click on that and click Properties. I will show a screenshot of the click location because it’s the right thing to do, but this context menu is gigantic and Properties is all the way at the other end of it, so I’m trusting you to find that on your own.
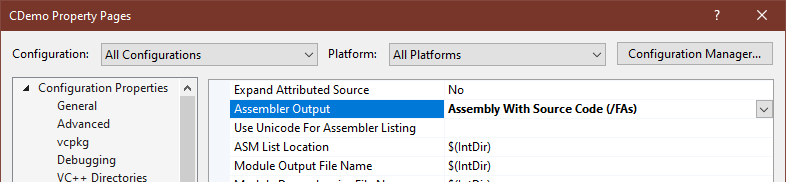
- In the Properties dialog, navigate to Configuration Properties > C/C++ > Output Files. In the right pane, change the option for Assembler Output to Assembly with Source Code (/FAs). Click OK.
- On Visual Studio’s top menu, go to Build and click Build Solution.

- On Visual Studio’s top menu, go to File, Open, and click File…
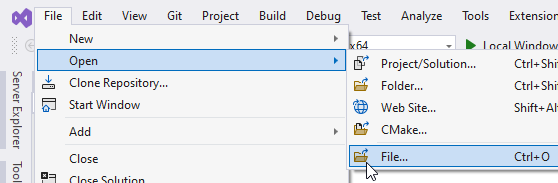
- Visual Studio’s “Open File” dialog will take you to the root of your solution. Navigate to the x64 sub-folder and then the Debug folder. If you do not have an x64 folder, then you should have an x86 folder. If you do not have that either, then step 8 failed or you didn’t wait for it to finish or you have changed your Visual Studio settings in a way that I can’t predict. Inside your Debug folder, or whatever oddball place you sent your output to, locate the file with the name of your solution and an asm extension and double-click it. DON’T PANIC.
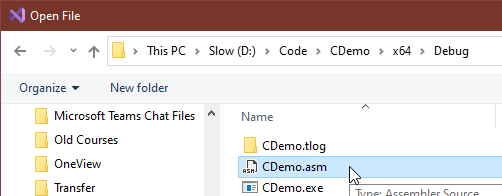
- If you panicked when the file opened, you did not follow step 10 closely enough. We care about less than 1 percent of the contents of this file. Press CTRL+F to open the finder flyout, type
std::cout, and press the arrow button.
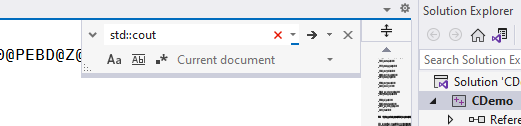
- Visual Studio will have skipped over a thousand lines to a section of about 25 that we want to see. It should have highlighted the
std::coutbit that you searched for, but the entire section starts withmain PROCand ends withmain ENDP.
I usually do this demo with a C file that doesn’t produce any output because it results in a lot simpler code. However, I wanted you to get started quickly, and this was a convenient way to show you the good, the bad, and the ugly all at once. I also chose Visual Studio as my demonstration platform because, as far as I know, Microsoft makes the only mainstream compiler that will output generated assembly side-by-side with the C or C++ source code.
For illustration, I pasted a chunk of the output from my machine below (for copyright and anti-plagiarism purposes, the Microsoft Visual C++ compiler in Visual Studio 2022 Version 17.5.1 produced this output code from C++ source code provided by Microsoft following the preceding instructions):
; 8 : std::cout << "Hello World!\n"; lea rdx, OFFSET FLAT:??_C@_0O@NFOCKKMG@Hello?5World?$CB?6@ mov rcx, QWORD PTR __imp_?cout@std@@3V?$basic_ostream@DU?$char_traits@D@std@@@1@A call ??$?6U?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@PEBD@Z ; std::operator<<<std::char_traits<char> >
We start with the line that begins ; 8; 9 contains the assembly language that the compiler generated from the code in line 8.
Outside of that, the code is a visual mess. A lot of that comes from the combination of the #included code in the header files that allow std::cout to do its work and C++’s much-maligned “name mangling”. C++ allows programmers to use the same name for different functions as long as they have different parameters (called overloading), but the machine requires guaranteed-unique symbol names. C++ gives the programmer and the machine what they want with behind-the-scenes “mangling”. Probably the only thing that will ever mean to a sysadmin is to explain some of the gibberish characters in a hex dump. That’s not high value knowledge for us, which is one reason I do not recommend C++ for this undertaking. The rest of the bulk, probably most of it, comes from running the compiler in debug mode. We’ll revisit that.
A Simpler C Example
I started this segment intending to get you to look at machine code that you can understand. So, starting from where you left off with the generated assembly from the default C++ program, switch back to the C++ source file. You do not need to close the assembly file. Delete everything in the .cpp file and replace it with this:
int main()
{
int a = 0;
a++;
return a;
}
This program will do nothing that you can see, so you won’t find anything interesting if you run it. If you want, you can rename it inside Visual Studio to have a .c extension, which will force Visual Studio to run it through its C compiler. The C++ compiler will produce the same code from this source, so it doesn’t matter if you do that. Let’s understand what the code does:
- Line 1: Every program requires an “entry point”. The entry point is the first line of code that the operating system calls to start the program. By convention, C and C++ associate the entry point with a specific function called “main” that returns an integer value. That’s what the
intmeans at the beginning of line 1: the return value of the function. The parenthesis after “main” would hold parameters. A program’smainfunction can accept arguments from the operating system, but this program does not, so we left the parentheses empty (they must exist or C would try to treat this as a variable called “main” instead of a function and get very confused). The open brace on line 2 just marks the beginning of the function. - Line 3 tells C to set aside a block of memory the size of its integer data type, label that block “a”, and place the integer value 0 in it.
- Line 4 tells C to increment the value of
a(see the note after this list). - Line 5 tells the function to return the value of
ato the caller, in this case, the operating system. Remember how we said thatmainreturns anint? The value ofais thatint. Line 6 just indicates the end of the function, and, since this is themainfunction, the end of the program.
Note: Right now, someone is fuming over line 3. I know what upset you. Please wait, I’ll get to that.
Use the Build > Build Solution menu path like before to compile the code and generate the output. Switch back to the tab that contains your assembly (or reopen the file). You’ll first notice that this output has over a thousand fewer lines than the earlier C++ file. This program does basically nothing and doesn’t include any other code. It still has a bit of extra for debugging. I have pasted the interesting parts of the output below:
; 3 : int a = 0; mov DWORD PTR a$[rbp], 0 ; 4 : a++; mov eax, DWORD PTR a$[rbp] inc eax mov DWORD PTR a$[rbp], eax ; 5 : return a; mov eax, DWORD PTR a$[rbp] ; 6 : } lea rsp, QWORD PTR [rbp+232] pop rdi pop rbp ret 0
Visual Studio’s compiler inlined the C source with the assembly that it generated, making this a simple walkthrough. Line 3 sets apart an int-sized spot of memory and inserts the value 0. This assembly has an “$a” that matches the variable name in C and [rbp]; both only exist so a debugger can keep track of what’s happening. Line 4 pops out to three lines of assembly: first, it copies the value from the memory location named “a” and places it into a CPU register. Second, it increments the value in that register. Third, it copies the value of the incremented register back to the “a” location. Line 5 then moves that value back into EAX. It does that because, when returning a value from a function, assembly (usually) places it into the accumulator register, which is some variant of “A” on every x86 and x64 processor I have seen. You’ll learn about these as you work through assembly tutorials. Line 6 generates 4 lines of code, but the first 3 are for debugging. The final one, ret 0, signifies the end of the function.
On to our next trick. Go up to the toolbar area of Visual Studio and change the drop-down that says Debug to Release. After that, rebuild your project again.
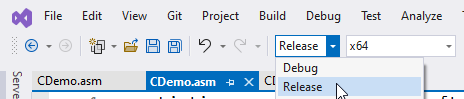
Go back through Visual Studio’s File > Open routine like you did in step 10, but this time, choose the Release folder instead of the Debug folder. You will see an .asm file with the same name as the one you found in the Debug folder. Open it. Look at the difference!
main PROC ; COMDAT ; 6 : int a = 0; ; 7 : a++; ; 8 : return a; mov eax, 1 ; 9 : } ret 0 main ENDP
The compiler turned your entire main function into a single line of assembly: mov eax, 1. It did that via intelligent optimization. The compiler read through your program and figured out that it would always send a 1 back to the operating system and keep nothing else, so it skipped all the storing and calculating and emitted just enough code to return 1.
Before I end this section, I’ll talk about that a++ line that might have upset some people. The pluses come after the variable, so we call it a “postfix” operator. It only affects a single variable, so we also call it a “unary” operator. In all languages that use it, the unary ++ operator means “increment by one”. The postfix form tells C (and most other languages) to perform all other operations in the statement first, then increment the variable. In more precise, although maybe not as clear terms, a postfix ++ has low priority compared to other operators. That can lead to unexpected behavior. In single action statements like that line, it also suggests unnecessary work since postfix implies that the current value needs protection from other activities in the statement. It does not need that as I’ve used it, so technically, I told C to do something wasteful. However, every mainstream compiler will optimize any intermediate steps away in this usage. If you want to always guarantee that your compiler or interpreter will increment the variable at the exact point it finds it, then use a prefix operator: ++a. If you go on to serious programming, you need to know this. For me, I always use the postfix and I always perform increments as a solitary action. If you search around, you will eventually encounter things like p++ == ++q. Those constructs can confuse even people that know what they mean. Putting them into production code doesn’t make it less confusing. Also, even though it might result in less typed code, it rarely makes any difference in the final machine code than just separating the increment(s). After the above experiments, you now know how you could prove that. In my daily work, I almost always encounter unary operators in postfix form. When I see prefix operators, I pay closer attention. So, good practice guideline: use the postfix and perform increments as the only action in a statement. It makes your code easier to read and less prone to subtle bugs.
Recap of the C Introduction
The moment spent on the C++ program showed the differences between apparent difficulty of code and actual difficulty for the computer. You wrote no code of your own and Microsoft’s sample was short and simple. When you looked at the generated assembly, you saw how much work the computer needed to do for such a “simple” program. That’s important knowledge because sometimes you will encounter code and script that looks short and sweet but swells up when turned into machine code. The sample used debug mode to exaggerate the problem. If you like, you can repeat the experiment in release mode to get a more accurate idea of how this would play out with non-trivial programs.
After the C++ work, you built a simple C program and examined its unoptimized assembly output. This helps you to make connections between what you type and how that translates to machine code. It also helps you to see why someone might claim that they “script in C”. Compilers and interpreters handle an enormous amount of busy work for you. C also reduces the amount of things that you can only learn through rote memorization. For example, EAX is a general purpose CPU register, but it’s also the accumulator register, so some instructions will overwrite anything you put there, but it’s also the register that most callers will look in for a return code when a called function exits, so sometimes you have to put things there. Confused yet? Does anything about the phrase “EAX register” innately suggest any of that to you? Conversely, I bet you don’t need to think hard about the meaning of “if” or “return” in programming languages.
After the debug mode C build, you rebuilt in release mode and examined its optimized assembly output. This helps you to understand that the computer might “think” through your code and clean up your inefficiencies. As an important side effect for sysadmins and scripters to note, sometimes the software runs in ways that do not match the typed code. It should always have the same outcome. Otherwise, the compiler or interpreter has a bug. Another important point: you do not need to obsess over writing the most efficient code possible. Let the computer worry about that (but still, take care, because it can’t fix everything).
C for Yourself
Oh look, another terrible pun. Ha. At least I did not need to explain this one. I hope. Don’t worry, this will all be over soon.
I encourage you to spend some time learning C for the same purpose that I wanted you to learn some assembly. You do not need to reach proficiency. Get an idea for the way that programmers build code and how that translates to what the machine does.
Like assembly, I learned C from books that you probably can’t find anymore and don’t include the language updates of the past couple of decades. Some C resources that I found:
- C Tutorial on Tutorialspoint: I find the quality of Tutorialspoint a bit hit or miss. From my skim of the C material, it seems OK. The ads are obnoxious and make my computer fussy, but at least I did not encounter any popups.
- Coding Unit: The C tutorial on Coding Unit spends more time exposing you to C than Tutorialspoint. It also has slightly less annoy ads. However, I found the navigation and organization clumsier. Also, some people learn better through exposition, so maybe this site won’t work for you. Since I want you to understand the concepts more than the language, I ranked this site second.
Several excellent C books exist, but I would not recommend spending money on C materials to a sysadmin. Few people write net-new C code anymore. If you want to program as a sysadmin, you have more suitable choices.
The Goal of Learning Assembly and C
I promise, no more low-level language stuff. If you skimmed the assembly and C sections and did not pick up the value of learning them, then please read this section.
Computing facts that impact scripting but will not seem obvious unless you know how computers work:
- All data types in all languages are fake. The computer sees everything as bits. It knows that bits entered a certain way mean an instruction that it must carry out. The closest that it gets to distinguishing data types is a few processor registers dedicated to floating-point values. As you explore C, you will discover primitive data types (
int,char,double, etc.) and slightly less primitive types (arrays,structs, andunions). Higher-level languages, including scripting languages, introduce even more complicated types (classes, strings, lists, etc.). But, when you look at the assembly generated from any of those languages, you will see no data types. At most, you will see data sizing indicators BYTE and WORD and their variants. - The CPU does its work in registers. C and higher-level languages allow you to write complicated statements. To get the CPU to execute them, a compiler or interpreter must break them down into simple, single-action instructions. Furthermore, the CPU can only directly read and change data in its registers. A CPU does not have as many registers as you might expect, and some of them have very narrow purposes. Of special note, a register is the same size as the “bitness” of the CPU. A 32-bit CPU has 32-bit registers, a 64-bit CPU has 64-bit registers, and so on. The BYTE and WORD size variants mentioned in the last bullet point can designate a subset of a register. That way, a 32-bit CPU can operate on 4 bit or 8 bit or 16 bit chunks. It cannot, however, work on a 64-bit chunk without some trickery involving two registers. Just imagine what it needs to do to work with larger, complicated “data types”. With only a few registers, imagine what it needs to process thousands of data points.
- Computers are not smart. Clever optimizations and advancements in AI give the impression that the machines are smart. They are not. I do not know how far away we are from CPUs or something similar that anyone would recognize as intelligent, but I do know that the x86, x64, ARM, and other processors in common use do not come close. Computers do things with blinding speed, but they do exactly as they’re told, even when it makes no sense. They do not know better.
With only an introductory level of assembly and C knowledge, these things become obvious. They become useful when you’re scripting or reading someone else’s script. Take string concatenation for example. Most high-level languages (not C) allow you to concatenate strings with the same syntax that you use to add numbers. So, 2 + 7 for numbers on the one hand, and “the beginning” + ” and the middle ” + “and the end” on the other. After a brief spin with assembly and C, you can look at the first and surmise, “I can tell the CPU to place 2 in a register and then ADD 7.” But what about the strings? How would you tell the CPU to do that? Whatever you come up with, it will significantly exceed two instructions and the space of a couple of registers.
In my daily work, I often encounter scripts with loops that parse some data and build it into an output string. My scripting language of choice, PowerShell, offers the + operator for strings. While that might seem bad based on the previous paragraph, the work to concatenate a few short strings does not amount to a meaningful load. However, running through thousands of lines of a file or a SQL report and continually adding a few characters to the same string requires significant effort. The code looks simple, but it can chew up memory and bog down the processor. To not dump this problem on you and run off, I found an article that uses the same solution for non-trivial string composition that I would pick and for the same reason. For my article, I want you to realize that if you have paid attention up to this point, you already have some understanding of why such a process would be slow, while the person who wrote the code probably just wonders why it takes forever. I hope that you also see that this represents a limitation of the compiler’s or interpreter’s ability to optimize your code.
I’ll stop this line of thought here and encourage you to go out and find out what other things you can learn with just a little peeking into the machine. I want to end with one of the most valuable things it taught me: whether interpreted, fully compiled, or run through some sort of on-demand compilation (usually called Just-In-Time, or JIT), all code becomes machine instructions. If you want, you can attach a debugger to a process running interpreted code and prove it. That’s non-trivial, but not impossible.
Anyway, while “fully compiled” code is faster end-to-end, the other kinds of code become nearly as fast after initial ramp-up. Modern computers perform that so quickly that most of the time spent on it disappears under the time spent performing I/O to load the program from storage. So, even though “fully compiled” may mean better performance, it almost never matters. For the things that sysadmins do, “scripting” and interpreters and the other things that self-styled “real” programmers sneer at do not matter in the slightest.
As a reward for suffering through all that, I found an amazing document. It starts off by calling itself a guide to Windows assembly, but I do not think that does it justice at all. It certainly shows assembly, but it interleaves CPU architecture and functionality and a bit of C. If you have enough background, it’s an easy, well-structured read. If you get to the end, I would say that you know plenty for a sysadmin. You can find this article on sonictk.github.io.
Getting Started with Scripting
After a few thousand words proclaiming that scripting and programming have no meaningful distinction, let’s talk about scripting. For the record, I wholeheartedly believe what I said. Common usage says that the things I’m talking about now are scripting languages. I would have a difficult time convincing anyone that I don’t care what they call it if I fight against that.
I prefer PowerShell for many reasons. It runs on every operating system that I use. PowerShell has all the power of a “real” programming language if I need it. The “Shell” part of the name indicates that it’s a shell, which means that I can use it to directly manipulate the operating system.
For you, use the tool that does the best job for you. I despise Perl, but if it works for you and gets the job done, I won’t criticize you for using it. If you spend significant time in Linux, then I foresee bash scripting in your future. That type of scripting comes from a time when there was little language involved. It mostly connects utility programs with decision branching. You will spend more time becoming familiar with the GNU utilities than anything linguistic. Again, no harm and no judgment. If that solution works best for you, use it.
I don’t have many resources for bash scripting. I use Linux, but I have such minimal scripting needs that I search the Internet for whatever I want to accomplish. You can do the same in PowerShell, from beginner to advanced user. Still, PowerShell has a complete language of its own, and it can directly access the entirety of .Net. Therefore, it helps to learn it as a language, not just as a place that you occasionally type a line or two that you found on the Internet.
Start by getting a copy of the latest release of PowerShell. I also recommend Visual Studio Code, if you do not already have it. If you open a .ps1 file in VS Code, it will recommend the PowerShell extension. I suggest following that recommendation.
Now, for some resources to help you learn PowerShell:
- The PowerShell team’s root documentation page has highly valuable springboarding content.
- Microsoft’s Learn page for PowerShell has an adaptation of Mike Robbins’ book. Before joining Microsoft, Robbins was well-known in the PowerShell community for clear material that helped newcomers get going quickly. In addition to that, check the menus at the left for more learning content, including a resources page that will take you to more.
- You can find assistance on the PowerShell.org forums. The main PowerShell.org site also has a page of “free” resources. However, you can only get the books “free” if you have a paid membership on LeanPub. I believe that was due to a change on LeanPub’s part, not a deliberate attempt to mislead by the folks at PowerShell.org. They should probably update their wording, though.
- PSKoans is a way to learn PowerShell by doing. The authors have done a great deal of work to make it smooth and entertaining.
- PowerShell in Depth, Second Edition has aged, but still is one of the best start-to-finish PowerShell learning guides in existence. It also serves well as reference work.
- I have not read any version of PowerShell in a Month of Lunches myself. Now in its fourth edition, it has steadily held a top spot for years. I don’t recognize all the names in the current author list, but Don Jones and Jeffery Hicks have been giants in the PowerShell community for years. Both are known for high quality writing and training.
- Even more in-depth than PowerShell In Depth, Windows PowerShell in Action explores every deep corner of PowerShell. Few people will need it all, but it has it. I use and recommend this more as a reference work than training material, but you could use it to learn.
Unlike assembly and C, I do believe that sysadmins should invest money into learning PowerShell. You will use it. It will save you in ways that you will appreciate. Many more books exist on PowerShell, so look for ones that speak to you. Of course, if you want to go another way with scripting, do it. I have some books on Linux scripting, although I haven’t used them enough that I want to recommend anything.
Most of all, you learn by doing. If you already have a sysadmin job, think about the things that you do over and over and over. Look for ways to make PowerShell handle that repetition for you. If you don’t have a sysadmin job but want to get into the field, then find a learning method that works for you and learn.
We at Project Runspace do not plan to create start-to-finish PowerShell training resources (at least not at this time), but we will integrate and demonstrate it at every opportunity. Get scripting and get ready to outperform everyone that won’t take the time.